Serving Open Graph to Bots at hey.xyz
At hey.xyz, our main site is a fast client‑side React app (Vite + React Router 7). Humans love it. Crawlers don't. Most social bots and search engines read the initial HTML only; they don't execute your JavaScript, so client‑rendered pages ship almost no <meta> data to them.
We solved this with a small, clear split:
- Main Web App: CSR app on Cloudflare Pages
- OG Service: tiny SSR Next.js app on Railway that renders only metadata (no UI)
The glue is a Cloudflare Worker. It inspects the User‑Agent and:
- For humans: proxies straight to the CSR app
- For bots: routes to the OG service that returns fully formed
<head>metadata
TL;DR
- Keep the UI as CSR for speed and simplicity.
- Detect bots at the edge with a Worker.
- Serve a minimal SSR HTML page that contains correct Open Graph and Twitter Card tags.
- Cache bot responses aggressively (we use 30 days) for low cost and high throughput.
This is the Cloudflare interface where we connect the Worker with the web app.
We set a generous cache policy (30 days) for bot responses because our metadata changes infrequently.
This approach keeps the main app fast for people and properly descriptive for bots. No need to SSR the entire app just to satisfy crawlers.
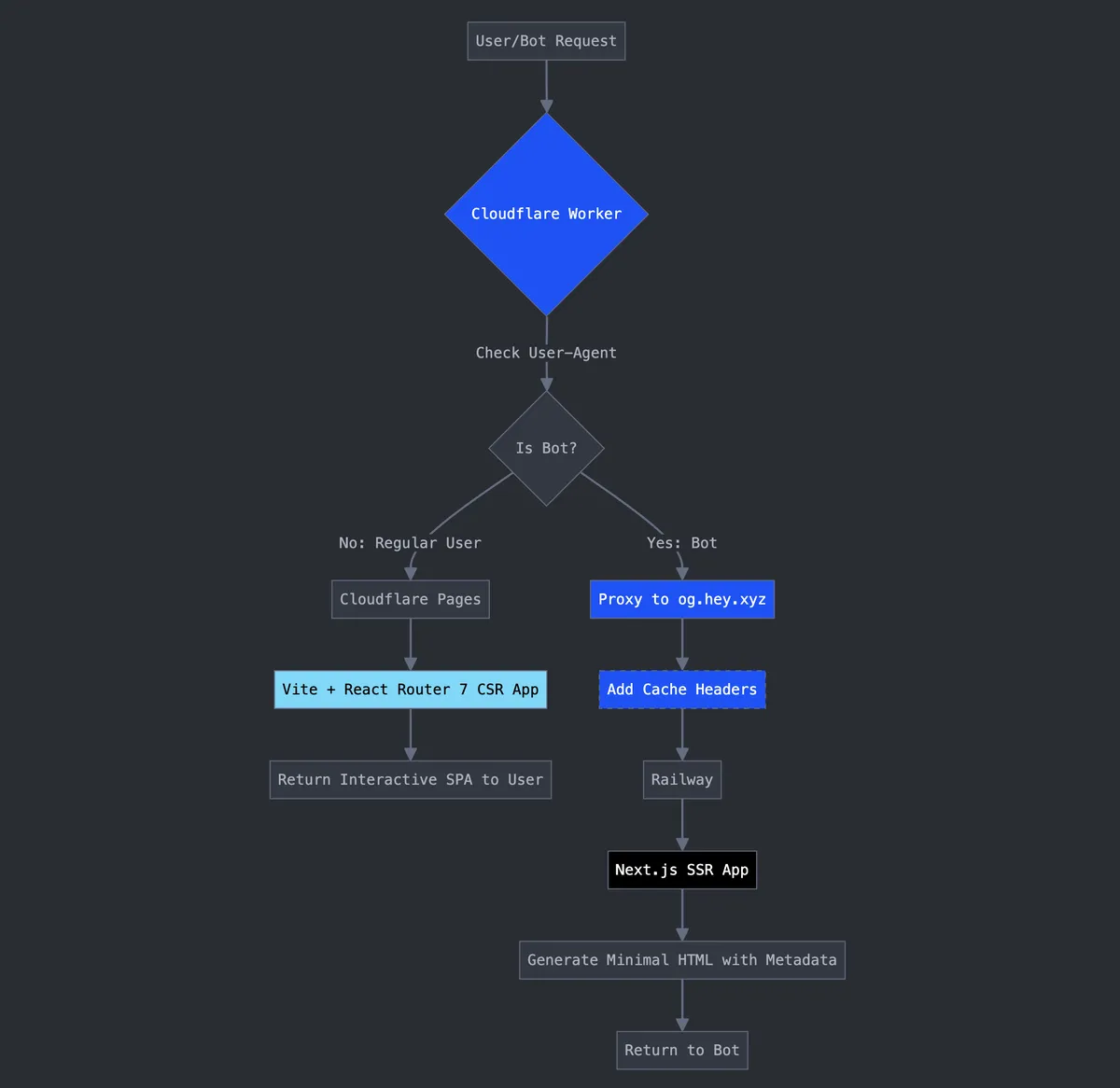
Here is the flow diagram of how things work.
The Problem
Social networks and chat apps (Twitter/X, Facebook, LinkedIn, Slack, Discord, Telegram, WhatsApp) generate rich previews by scraping your page's HTML. If your HTML only contains a bare app shell, there's no og:title, og:description, or preview image for them to read.
Classic fixes include server‑rendering your entire site or pre‑rendering static HTML for every route. Both are heavier than we need for a primarily interactive CSR app.
Our Architecture
- CSR App (Cloudflare Pages): What humans interact with. No SSR necessary.
- OG Service (Railway, Next.js SSR): Returns minimal HTML with correct meta tags based on the requested path.
- Cloudflare Worker (Edge): Detects bots by User‑Agent and routes accordingly; adds long‑lived cache headers.
This split keeps concerns clean: UI stays simple and fast, metadata stays accurate and cheap to serve.
Cloudflare Worker: Bot Detection and Routing
We match common bot User‑Agents and route those requests to og.hey.xyz. Everyone else goes to the CSR site.
const botRegex = /(Bot|Twitterbot|facebookexternalhit|LinkedInBot|Slackbot|Discordbot|TelegramBot|WhatsApp|Googlebot|Bingbot|Applebot)/i;
export default {
async fetch(request) {
const ua = request.headers.get("user-agent") || "";
if (!botRegex.test(ua)) {
return fetch(request);
}
const url = new URL(request.url);
const target = `https://og.hey.xyz${url.pathname}${url.search}`;
const rewritten = new Request(target, {
method: request.method,
headers: request.headers,
body: ['GET', 'HEAD'].includes(request.method) ? null : await request.text(),
redirect: "follow",
});
const resp = await fetch(rewritten);
const headers = new Headers(resp.headers);
headers.set("Cache-Control", "public, max-age=2592000, immutable");
return new Response(resp.body, {
status: resp.status,
statusText: resp.statusText,
headers,
});
}
};
Notes
- The regex is intentionally broad; adjust as your traffic evolves.
- We forward method and headers so bots receive an authentic response.
- We add a long cache so repeated crawls are effectively free.
The OG Service: Minimal SSR, Maximum Metadata
The OG service maps the incoming path to content metadata and returns HTML with the right tags. You can use Next.js App Router and generateMetadata to render <head> only.
Next.js (App Router) example
// app/[...slug]/page.tsx
import type { Metadata } from "next";
async function getMetaForPath(path: string): Promise<{
title: string;
description: string;
image: string;
}> {
// Lookup in your CMS, database, or static map
// For demo purposes, return a fallback
return {
title: `hey.xyz - ${path}`,
description: "Open Graph metadata served specifically for crawlers.",
image: `https://cdn.hey.xyz/og${encodeURIComponent(path)}.png`
};
}
export async function generateMetadata({ params }: { params: { slug?: string[] } }): Promise<Metadata> {
const path = `/${(params.slug || []).join("/")}` || "/";
const meta = await getMetaForPath(path);
return {
title: meta.title,
description: meta.description,
openGraph: {
title: meta.title,
description: meta.description,
images: [{ url: meta.image }],
type: "website",
url: `https://hey.xyz${path}`
},
twitter: {
card: "summary_large_image",
title: meta.title,
description: meta.description,
images: [meta.image]
}
};
}
export default function Page() {
// We don't need to render UI for bots - metadata is the goal
return null;
}
If you prefer, you can return a tiny HTML document with just <head> for absolute control. The key is that the OG service is cheap to render, quick to cache, and independent from your main UI.
Testing
Quickly verify routing and metadata with curl:
# Human (no special UA) - should hit CSR app
curl -i https://hey.xyz/some/route
# Bot - should be routed to OG service
curl -A "Twitterbot/1.0" -i https://hey.xyz/some/route
Also drop links in Slack/Discord to confirm previews, and use each platform's debug tools (e.g., Facebook Sharing Debugger, Twitter Card Validator, LinkedIn Post Inspector).
Caching & Freshness
- We cache bot responses for 30 days via the Worker. Bump or bust the cache when your content changes materially.
- For frequently updated pages, consider a shorter TTL or versioned image URLs (e.g.,
?v=123).
Pitfalls & Tips
- Some platforms send
HEADrequests first; ensure your OG service responds consistently. - User‑Agent strings evolve; keep an eye on logs and update the regex.
- Don't leak private or draft content via open routes.
- If your OG image is dynamic, ensure it is also cached or generated quickly.
Results
This pattern keeps interaction snappy for real users while giving crawlers everything they need. It's simple to operate, cheap to run at scale, and easy to evolve independently from the UI layer.
P.S. The Worker snippet above is exactly what we run in production, with cache headers tuned for our needs.